YottaDynamics Technical Notes
Infrastructure, AI agents, and platform engineering — written for engineers building production systems.
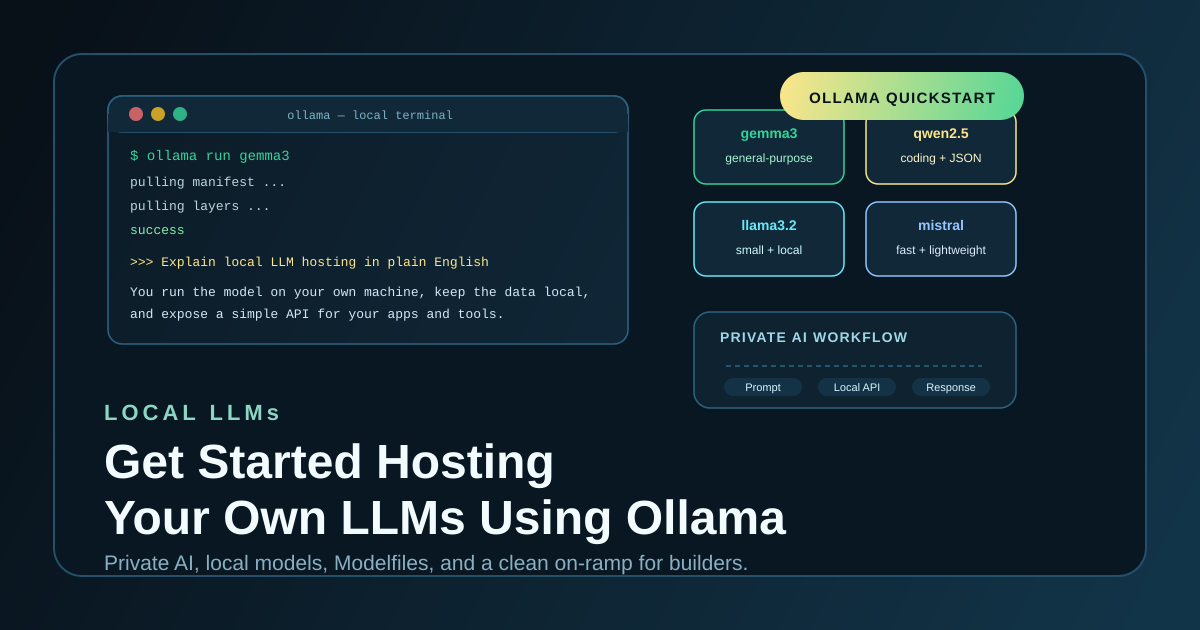
Ollama is one of the fastest ways to move from cloud API dependency to local model serving on your own machine. This guide covers installation, first-run commands, model selection, Open WebUI, Modelfiles, and basic API usage.

Monitoring an agent is not the same as monitoring a service. The question shifts from whether it is running to whether it is reasoning correctly — and that requires a different observability stack built around structured traces, quality metrics, and cost attribution.

Non-deterministic systems require evaluation strategies that traditional QA cannot provide. Closing the gap requires a golden dataset, trajectory analysis, an LLM-as-judge pipeline, and a feedback loop that runs before every deployment.

LLMs are stateless by design. Memory is the external infrastructure that turns them into agents that learn from experience, remember preferences, and actually improve over time. Here’s how it works — technically.
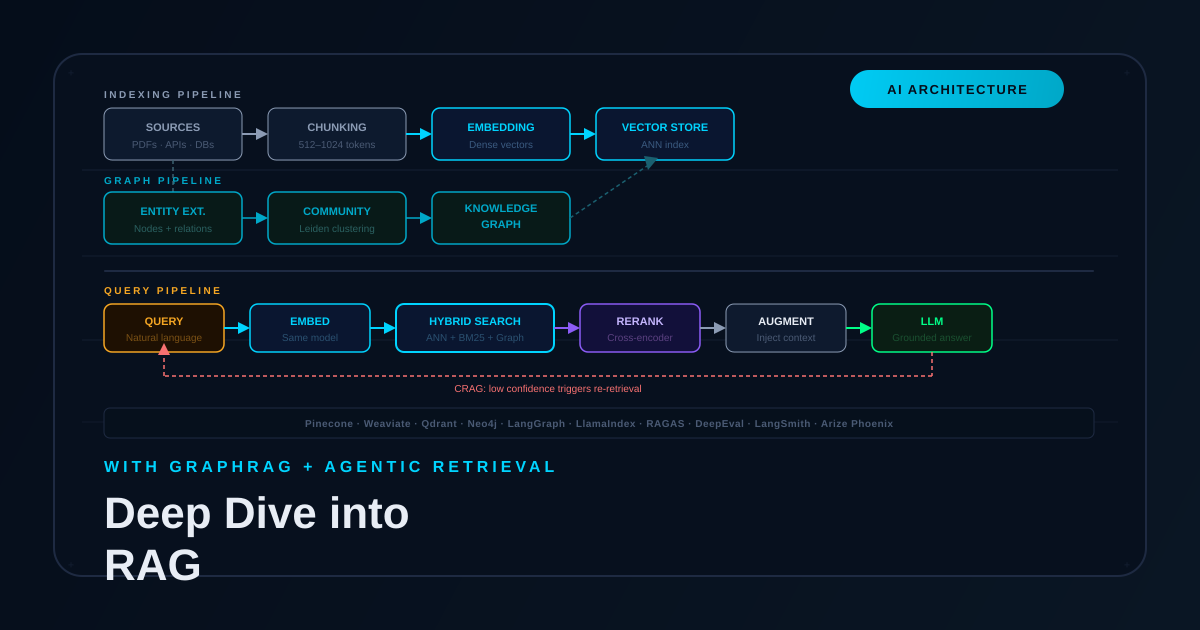
RAG fixes the core problems with pure LLMs — hallucination, stale knowledge, private data — by making retrieval a first-class citizen. Here’s the full technical picture: vector search, hybrid retrieval, GraphRAG, agentic patterns, and what a production stack actually looks like in 2026.
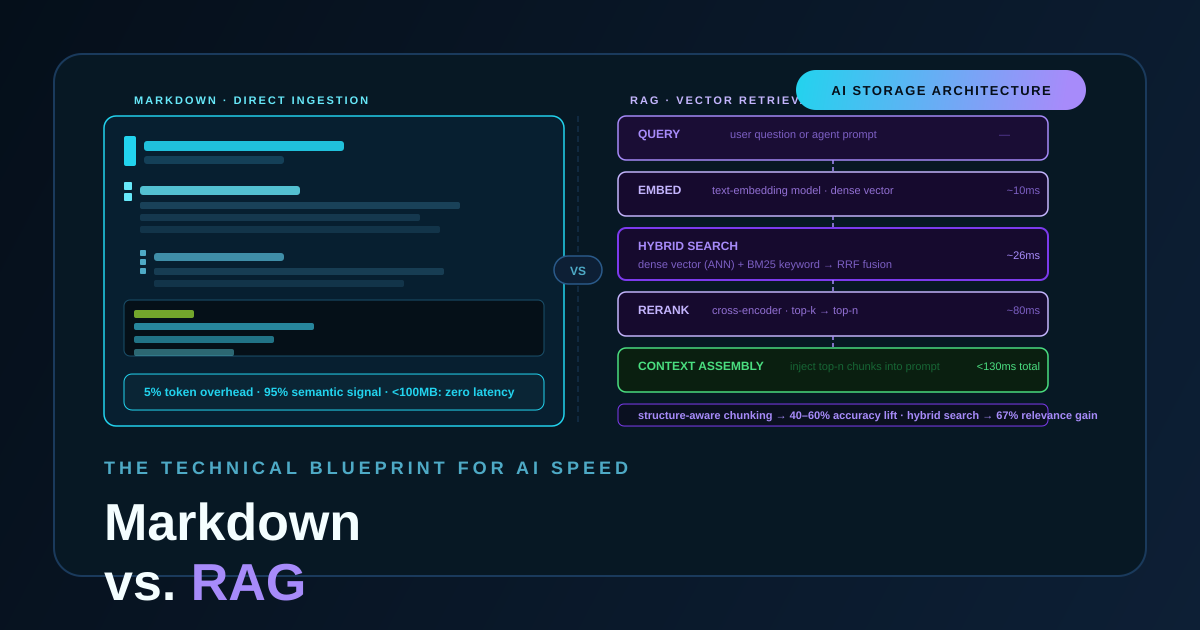
The storage format you choose for AI knowledge directly shapes your system’s latency, token density, and semantic clarity. A pragmatic breakdown of when to use raw Markdown, when to build a RAG pipeline, and why the best production systems use both.
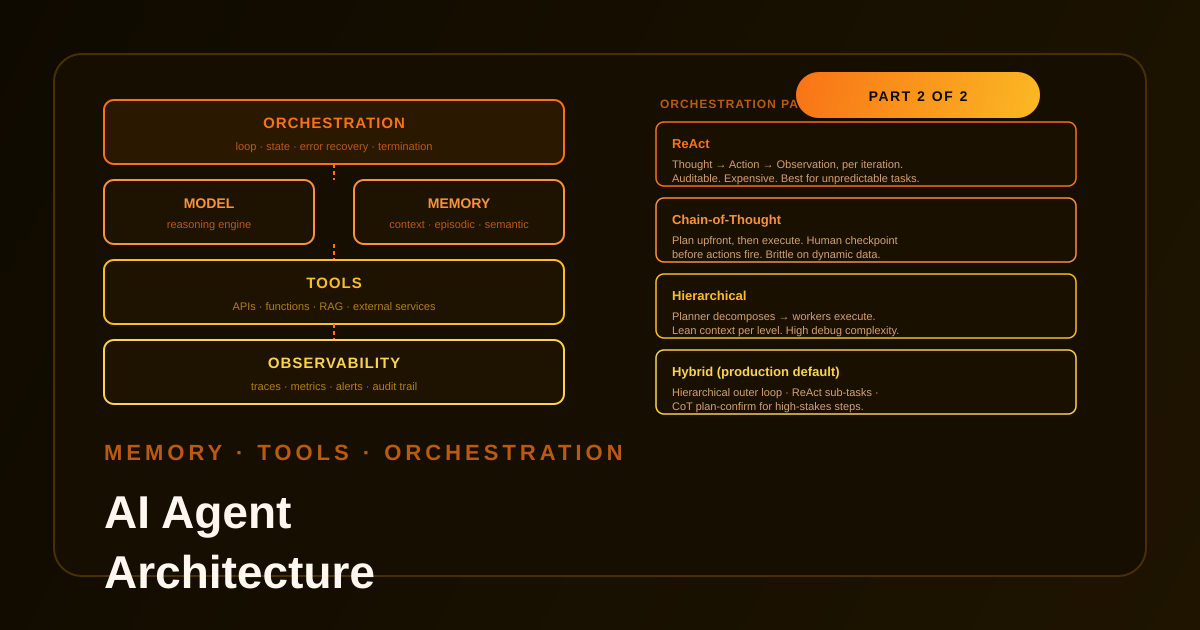
Most ‘my agent broke’ investigations don’t end at the model. They end in memory design, tool scope, orchestration logic, or missing observability. This post covers the plumbing that actually determines whether an agent works in production.

A deep-dive into every layer of a production-grade, fully open-source stack for self-hosting large language models — from the API gateway to the GPU compute plane.
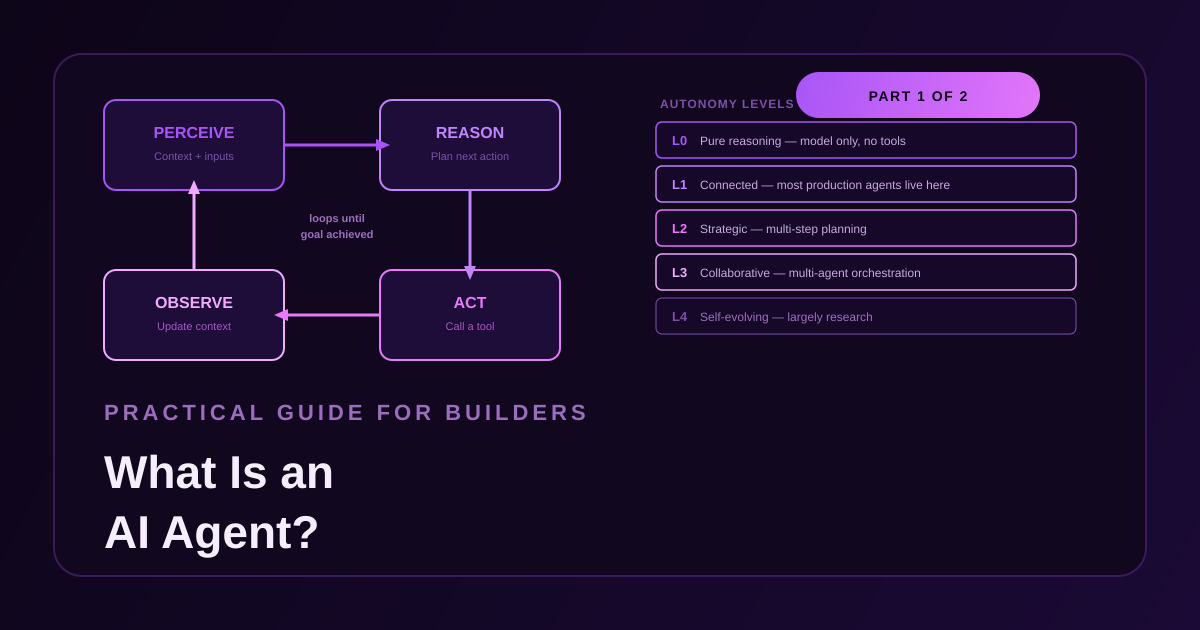
The term ‘AI agent’ gets applied to everything from a ChatGPT thread with a button to systems that autonomously manage deployments. That imprecision directly shapes the architectures you choose and the failure modes you inherit.

Most teams use Claude Code like a smart autocomplete. The teams getting real leverage treat it as an engineering platform — with CLAUDE.md, permissions, hooks, sub-agents, skills, and CI/CD integration designed in from the start.
New posts delivered to your inbox. No noise.
Prefer RSS? Subscribe via feed · Powered by Buttondown