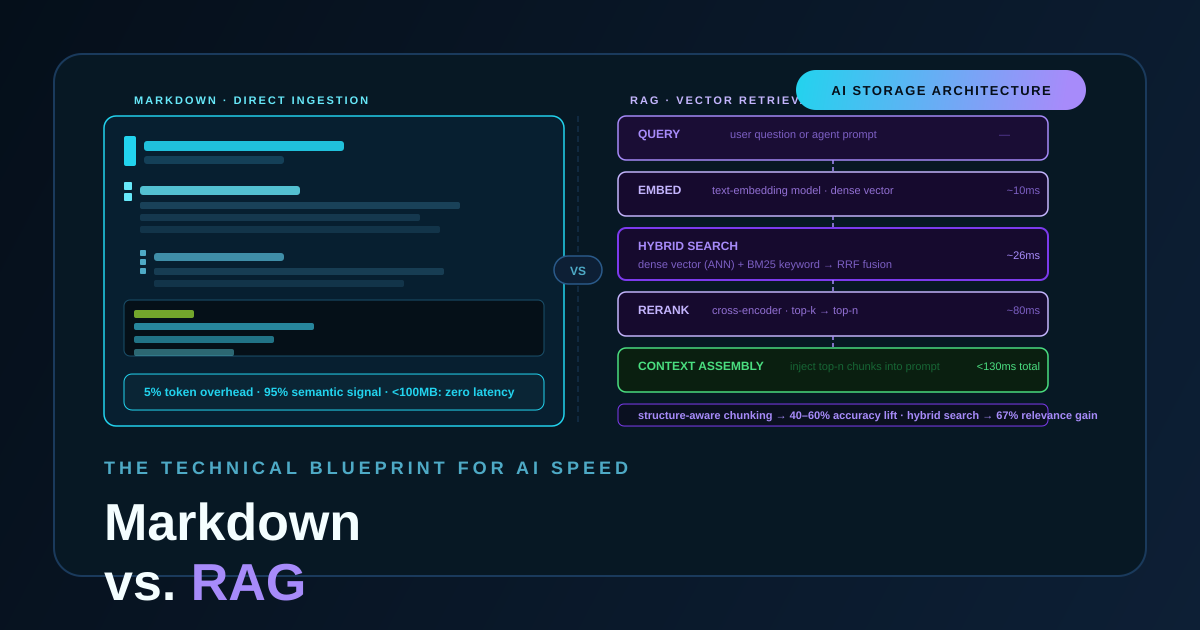
The Technical Blueprint for AI Speed: Markdown vs. RAG
The storage format you choose for AI knowledge directly shapes your system’s latency, token density, and semantic clarity. A pragmatic breakdown of when to use raw Markdown, when to build a RAG pipeline, and why the best production systems use both.

