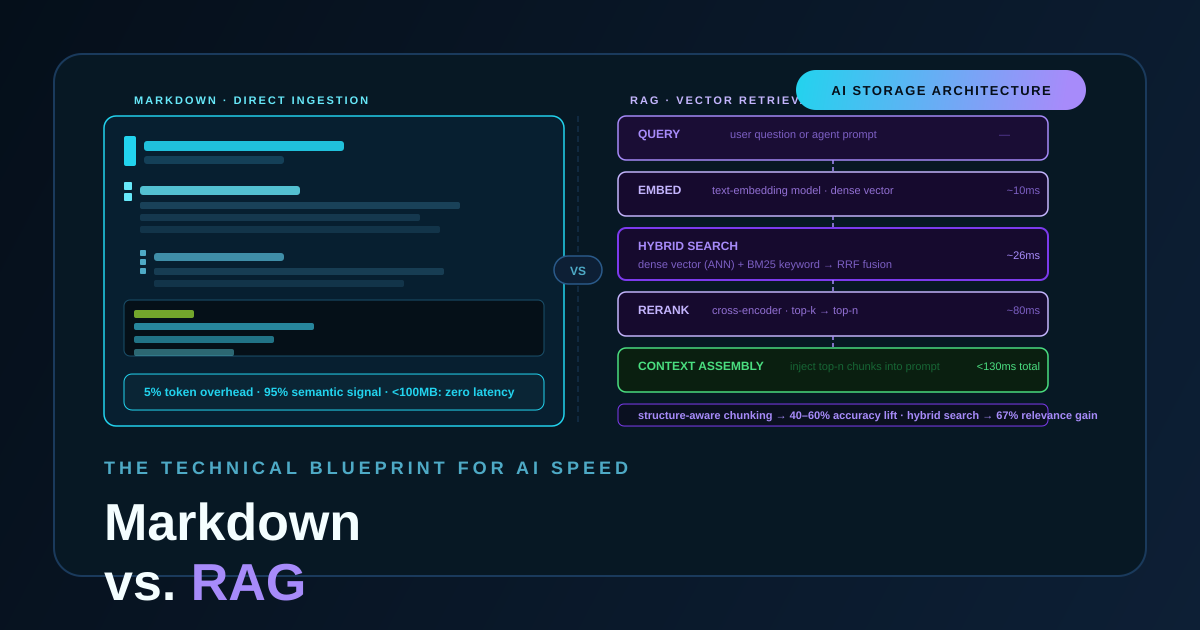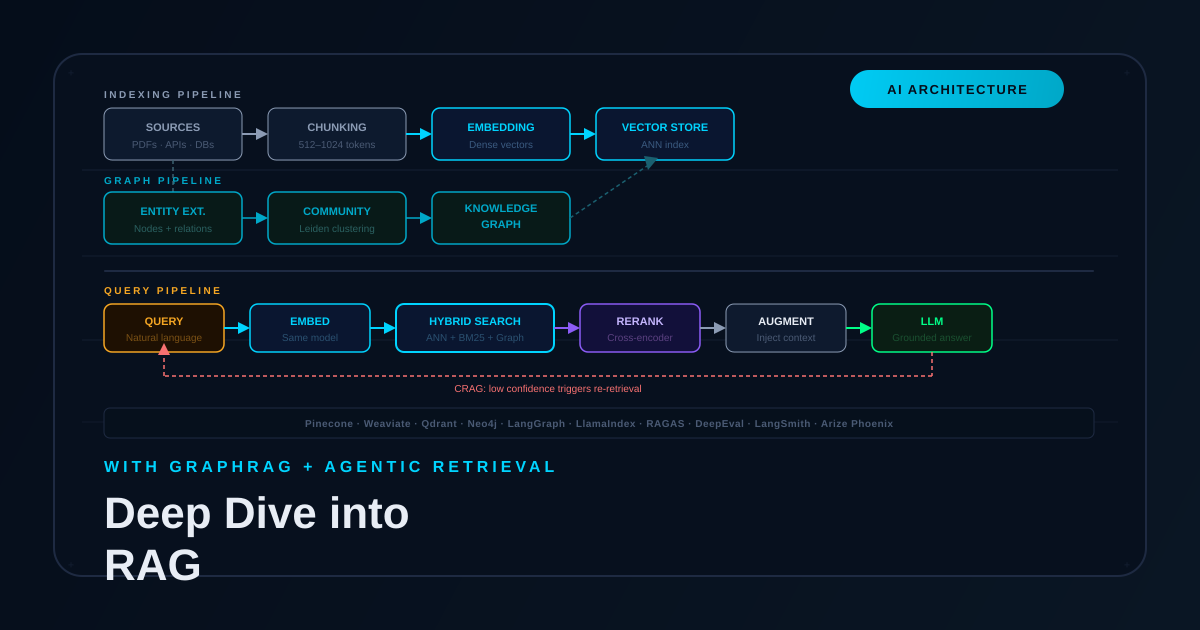
A Deep Dive into Retrieval-Augmented Generation (RAG)
RAG fixes the core problems with pure LLMs — hallucination, stale knowledge, private data — by making retrieval a first-class citizen. Here’s the full technical picture: vector search, hybrid retrieval, GraphRAG, agentic patterns, and what a production stack actually looks like in 2026.